
스레드의 동작 (feat. Python)
Process vs Thread
- 프로세스
- 운영체제로부터 할당받는 자원의 단위이다.
- 실행 중인 프로그램이다. (vscode, pycharm, chrome…)
- 각 프로세스마다 cpu와 메모리가 독립적이다.
- code, data, stack, heap이 각 프로세스마다 전부 독립적으로 사용된다.
- 최소 1개의 메인 스레드를 보유한다.
- 파이프, 소켓, 파일 등을 사용해서 프로세스간 통신이 가능하다. (context switching)
-
스레드
- 프로세스 내에서 실행되는 흐름의 단위이다.
- 프로세스의 자원을 사용한다.
- stack만 별도로 스레드마다 할당하고 나머지(code, data, heap)은 공유한다.
- 메모리를 공유한다. (변수 공유)
- 한 스레드의 결과가 다른 스레드에 영향을 끼친다.
- 동기화 문제는 정말 주의해야한다. (디버깅의 어려움)
- 멀티 스레드
- 한 개의 단일 어플리케이션(하나의 프로세스)이 여러 스레드로 구성되어 작업을 처리
- 자원 공유 문제 (교착 상태)
- cost 비용이 낮음 (하나의 프로세스의 자원을 공유하기 때문에)
- 스레드간 통신이 쉬움
- 멀티 프로세스
- 한 개의 단일 어플리케이션(하나의 프로세스)이 여러 프로세스로 구성되어 작업을 처리
- 한 개의 프로세스 문제 발생은 확산이 없음 (각각의 프로세스가 독립된 자원을 가지기 때문에
- 캐시 체인지, cost 비용이 매우 높음 (오버헤드)
- 프로세스간 통신이 어려움
https://kamang-it.tistory.com/entry/Go18고루틴과-동시성-프로그래밍쓰레드를-대체한다
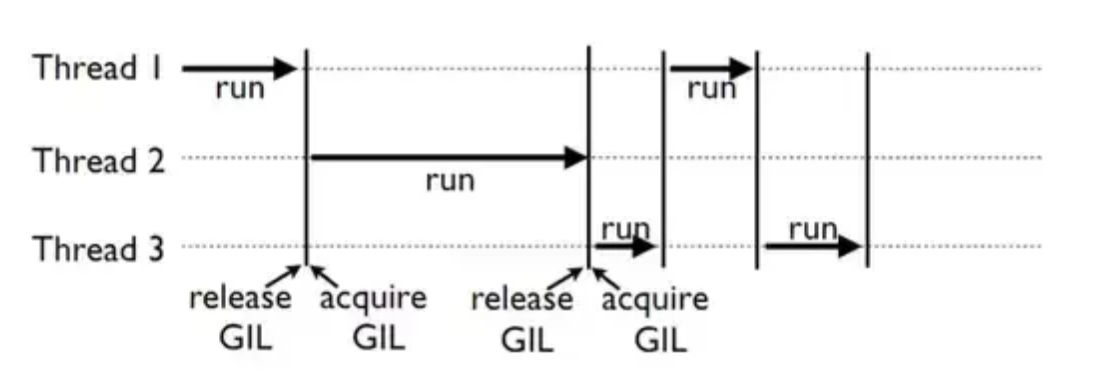
GIL (Global Interpreter Lock)
- 파이썬 고유의 멀티스레드 방식 (결론은 싱글 스레드로 동작하는게 제일 좋다….)
- python코드를 cpython이라는 컴파일러가 해석을 한다? → 바이트 코드로 바뀐다.
- GIL
- 단일 스레드만이 python object에 접근하게 제한하는 mutex (하나의 작업을 무조건 하나의 스레드로만 하는 것 - 싱글 스레드)
- 멀티 스레드로 하게 되면 cpython 메모리 관리가 취약하다 (not thread-safe)
- 멀티 스레드로 해야하는 작업은 거의 I/O
- 멀티 프로세스를 하면 된다.
- 병렬 처리는 멀티 프로세싱과 asyncio 등을 사용하면 된다.
기본 Thread 기본동작
def sub_thread(name):
logging.info('%s start!!!', name)
time.sleep(3)
logging.info('%s finish!!!', name)
if __name__ == '__main__':
logging.basicConfig(format='%(asctime)s - %(message)s', level=logging.INFO, datefmt='%H:%M:%S')
logging.info('Main-thread : before creating thread')
x = threading.Thread(target=sub_thread, args=('Sub Thread',))
logging.info('Main-thread : after creating thread')
x.start()
# 자식 스레드의 작업을 기다려준다.
# x.join()
logging.info('Main-thread : end')
22:33:18 - Main-thread : before creating thread
22:33:18 - Main-thread : after creating thread
22:33:18 - First Sub Thread start!!!
22:33:18 - Main-thread : end
22:33:21 - First Sub Thread finish!!!
Process finished with exit code 0
Daemon Thread
- 백그라운드에서 실행
- 자식 스레드가 아무리 작업을 하고 있어도 메인 스레드가 종료되면 즉시 모든 이외의 스레드들을 종료
- 백그라운드 무한 대기 이벤트 발생 실행하는 부분을 담당 (jetbrain의 자동저장, jvm의 gc, 크롬의 탭들…)
- 메인 스레드는 문서를 작성하는 작업이고
- 데몬 스레드는 자동저장하는 작업
import logging
import threading
def sub_thread(name, r):
logging.info('%s start!!!', name)
for i in r:
logging.info(i)
logging.info('%s finish!!!', name)
if __name__ == '__main__':
logging.basicConfig(format='%(asctime)s - %(message)s', level=logging.INFO, datefmt='%H:%M:%S')
logging.info('Main-thread : before creating thread')
x = threading.Thread(target=sub_thread, args=('First Sub Thread', range(2000)), daemon=True)
y = threading.Thread(target=sub_thread, args=('Second Sub Thread', range(1000)), daemon=True)
logging.info('First Sub Thread is daemon? : %r', x.isDaemon())
logging.info('Second Sub Thread is daemon? : %r', y.isDaemon())
logging.info('Main-thread : after creating thread')
x.start()
y.start()
# 메인스레드가 종료되자마자 sub스레드들 즉시 종료된다. (why? 데몬스레드라서)
logging.info('Main-thread : end')
ThreadPoolExecutor
- python 3.2 이상 내장 라이브러리
- from concurrent.futures import ThreadPoolExecutor
- with 사용으로 스레드 생성, 라이프사이클 관리 용이
- 대기중인 작업 → queue → 완료 상태 조사 → 결과 또는 예외 → 단일화, 캡슐화
from concurrent.futures import ThreadPoolExecutor
import logging
def task(name):
logging.info('%s Sub Thread start!!!', name)
result = 0
for i in range(10001):
result += i
time.sleep(2)
logging.info('%s Sub Thread finish!!! - result : %d', name, result)
return result
def main():
logging.info('Main Thread start!!!')
with ThreadPoolExecutor(max_workers=2) as executor:
tasks = executor.map(task, ['First', 'Second', 'Third'])
logging.info(list(tasks))
logging.info('Main Thread finish!!!')
if __name__ == '__main__':
logging.basicConfig(format='%(asctime)s - %(message)s', level=logging.INFO, datefmt='%H:%M:%S')
main()
22:40:48 - Main Thread start!!!
22:40:48 - First Sub Thread start!!!
22:40:48 - Second Sub Thread start!!!
22:40:50 - First Sub Thread finish!!! - result : 50005000
22:40:50 - Third Sub Thread start!!!
22:40:50 - Second Sub Thread finish!!! - result : 50005000
22:40:52 - Third Sub Thread finish!!! - result : 50005000
22:40:52 - [50005000, 50005000, 50005000]
22:40:52 - Main Thread finish!!!
Process finished with exit code 0
Lock, Deadlock
- 세마포어(semaphore) : 프로세스간 공유된 자원에 접근 시 문제가 발생할 수 있어서 한 개의 프로세스만 접근 처리를 고안 → 경쟁 상태 예방
- 뮤텍스(mutex) : 공유된 자원을 여러 스레드가 접근하는 것을 막는 것 → 경쟁 상태 예방
- Lock : 상호 배제를 위한 잠금 처리 → 데이터 경쟁
- DeadLock : 프로세스가 자원을 획득하지 못해 다음 처리를 못하는 무한 대기 상태 (교착 상태)
- 스레드 동기화(thread synchronization) : 안정적으로 동작하도록 처리
- 세마포어 vs 뮤텍스 (https://velog.io/@conatuseus/OS-세마포어와-뮤텍스)
- 세마포어는 여러개의 화장실을 여러명의 사람들이 한 화장실에 한명이 들어가서 작업이 끝나면 나오고 하는 과정이고
- 뮤텍스는 무조건 하나의 화장실에 여러명이 계속 기다리며 작업이 끝나면 다음 사람이 들어가는 과정이다.
- 세마포어는 뮤텍스가 될 수 있지만, 뮤텍스는 세마포어가 될 수 없다.
- 아래 코드는 공유된 자원에 다수의 스레드가 동시에 접근하여 조작하여 값이 원하는대로 떨어지지 않는 동기화가 되지않은 문제점을 보여주는 코드이다.
import time
from concurrent.futures import ThreadPoolExecutor
import logging
class FakeDataStore:
def __init__(self):
# 공유된 자원 (heap)
self.value = 0
def update(self, s):
logging.info('%s Sub Thread start!!!', s)
# 스레드마다 갖고 있는 stack영역
# mutex, Lock등 동기화가 필요 (thread synchronization)
stack_value = self.value
stack_value += 1
time.sleep(0.1)
self.value = stack_value
logging.info('%s Sub Thread finish!!!', s)
def main():
logging.info('Main Thread start!!!')
store = FakeDataStore()
logging.info('FakeDataStore update method test start!!! // value : %d', store.value)
with ThreadPoolExecutor(max_workers=2) as executor:
for v in ['First', 'Second', 'Third']:
executor.submit(store.update, v)
logging.info('FakeDataStore update method test finish!!! // value : %d', store.value)
logging.info('Main Thread finish!!!')
if __name__ == '__main__':
logging.basicConfig(format='%(asctime)s - %(message)s', level=logging.INFO, datefmt='%H:%M:%S')
main()
17:59:22 - Main Thread start!!!
17:59:22 - FakeDataStore update method test start!!! // value : 0
17:59:22 - First Sub Thread start!!!
17:59:22 - Second Sub Thread start!!!
17:59:22 - First Sub Thread finish!!!
17:59:22 - Third Sub Thread start!!!
17:59:22 - Second Sub Thread finish!!!
17:59:23 - Third Sub Thread finish!!!
17:59:23 - FakeDataStore update method test finish!!! // value : 2
17:59:23 - Main Thread finish!!!
- 위 코드의 문제점을 Lock을 통해 해결한 것이 아래 코드이다.
import threading
import time
from concurrent.futures import ThreadPoolExecutor
import logging
class FakeDataStore:
def __init__(self):
# 공유된 자원 (heap)
self.value = 0
# 스레마다 독립적으로 가지고 있는 자원 (stack)
self._lock = threading.Lock()
def update(self, s):
logging.info('%s Sub Thread start!!!', s)
# 스레드마다 락이 걸려서 다른 스레드가 해당 작업을 할 때는 릴리즈가 되지않은 이상 작업을 하지 못하고 기다려야 한다.
with self._lock:
logging.info('%s Sub Thread has Lock', s)
stack_value = self.value
stack_value += 1
time.sleep(0.1)
self.value = stack_value
logging.info('%s Sub Thread release Lock', s)
logging.info('%s Sub Thread finish!!!', s)
def main():
logging.info('Main Thread start!!!')
store = FakeDataStore()
logging.info('FakeDataStore update method test start!!! // value : %d', store.value)
with ThreadPoolExecutor(max_workers=2) as executor:
for v in ['First', 'Second', 'Third']:
executor.submit(store.update, v)
logging.info('FakeDataStore update method test finish!!! // value : %d', store.value)
logging.info('Main Thread finish!!!')
if __name__ == '__main__':
logging.basicConfig(format='%(asctime)s - %(message)s', level=logging.INFO, datefmt='%H:%M:%S')
main()
18:08:45 - Main Thread start!!!
18:08:45 - FakeDataStore update method test start!!! // value : 0
18:08:45 - First Sub Thread start!!!
18:08:45 - First Sub Thread has Lock
18:08:45 - Second Sub Thread start!!!
18:08:45 - First Sub Thread release Lock
18:08:45 - First Sub Thread finish!!!
18:08:45 - Third Sub Thread start!!!
18:08:45 - Second Sub Thread has Lock
18:08:45 - Second Sub Thread release Lock
18:08:45 - Second Sub Thread finish!!!
18:08:45 - Third Sub Thread has Lock
18:08:45 - Third Sub Thread release Lock
18:08:45 - Third Sub Thread finish!!!
18:08:45 - FakeDataStore update method test finish!!! // value : 3
18:08:45 - Main Thread finish!!!
Producer-Consumer Queue
- Producer-Consumer Pattern
- 멀티스레드 디자인 패턴의 정석
- 서버 프로그래밍의 핵심 (데이터 생산자와 데이터 소비자)
- 주로 허리역할
- Python Event 객체
- Flag 초기값 0
- Set() → 1, Clear() → 0, Wait(1→리턴, 0→대기), isSet() → 현 플래그 상태 조회
import concurrent.futures
import logging
# 생산자
import queue
import random
import threading
import time
def producer(pipeline, event):
# 네트워크 대기 상태라 가정 (서버)
while not event.is_set():
message = random.randint(1, 11)
logging.info('Producer produce message %s', message)
pipeline.put(message)
logging.info('Producer got event set... producer exit...')
# 소비자
def consumer(pipeline, event):
# 응답 받고 소비하는 것으로 가정 or db저장
while not event.is_set() or not pipeline.empty():
message = pipeline.get()
logging.info('Consumer got message %s from pipeline queue (current queue size : %d)', message, pipeline.qsize())
logging.info('Consumer got event set... consumer exit...')
def main():
logging.info('Main Thread start!!!')
# queue 생성 (사이즈 중요)
pipeline = queue.Queue(maxsize=10)
# event 생성
event = threading.Event()
# 멀티 스레딩
with concurrent.futures.ThreadPoolExecutor(max_workers=2) as executor:
executor.submit(producer, pipeline, event)
executor.submit(consumer, pipeline, event)
# 실행시간 조정
time.sleep(0.1)
# producer, consumer의 상태를 종료시킴
event.set()
# 프로그램 종료
logging.info('Main Thread finish!!!')
if __name__ == '__main__':
logging.basicConfig(format='%(asctime)s - %(message)s', level=logging.INFO, datefmt='%H:%M:%S')
main()
23:05:14 - Main Thread start!!!
23:05:14 - Producer produce message 1
23:05:14 - Producer produce message 8
23:05:14 - Producer produce message 6
23:05:14 - Producer produce message 5
23:05:14 - Producer produce message 10
23:05:14 - Producer produce message 4
23:05:14 - Producer produce message 11
23:05:14 - Producer produce message 6
23:05:14 - Producer produce message 9
23:05:14 - Producer produce message 1
23:05:14 - Producer produce message 8
23:05:14 - Consumer got message 1 from pipeline queue (current queue size : 9)
23:05:14 - Consumer got message 8 from pipeline queue (current queue size : 8)
23:05:14 - Consumer got message 6 from pipeline queue (current queue size : 7)
23:05:14 - Consumer got message 5 from pipeline queue (current queue size : 6)
23:05:14 - Consumer got message 10 from pipeline queue (current queue size : 5)
23:05:14 - Consumer got message 4 from pipeline queue (current queue size : 4)
23:05:14 - Consumer got message 11 from pipeline queue (current queue size : 3)
23:05:14 - Consumer got message 6 from pipeline queue (current queue size : 2)
23:05:14 - Consumer got message 9 from pipeline queue (current queue size : 1)
23:05:14 - Consumer got message 1 from pipeline queue (current queue size : 0)
23:05:14 - Consumer got event set... consumer exit...
23:05:14 - Producer got event set... producer exit...
23:05:14 - Main Thread finish!!!
댓글남기기