
DB (2)
Cache
- 캐싱이란?
- 미리 읽어두었다가 다음에 이걸 다시 읽는 요청이 오면 빠르게 응답하기 위한 목적으로 쓰인다.
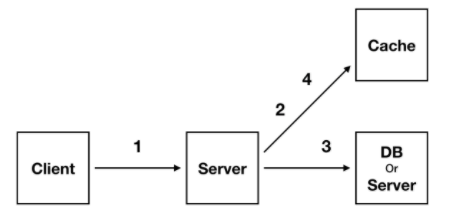
- 미리 읽어두었다가 다음에 이걸 다시 읽는 요청이 오면 빠르게 응답하기 위한 목적으로 쓰인다.
- redis란?
- 보통의 데이터베이스는 데이터를 디스크에 저장하고 IO연산으로 읽고 쓰는데
- redis는 디스크가 아닌 메모리에 저장하여 IO없이 엄청 빠르게 읽고 쓸 수 있다.
- 하지만 그렇기에 용량이 매우 작다. key - value 형식이다.
- 만료되어야 하는 인증토큰을 redis에 저장하여 관리하기 적합하다.
- 인증
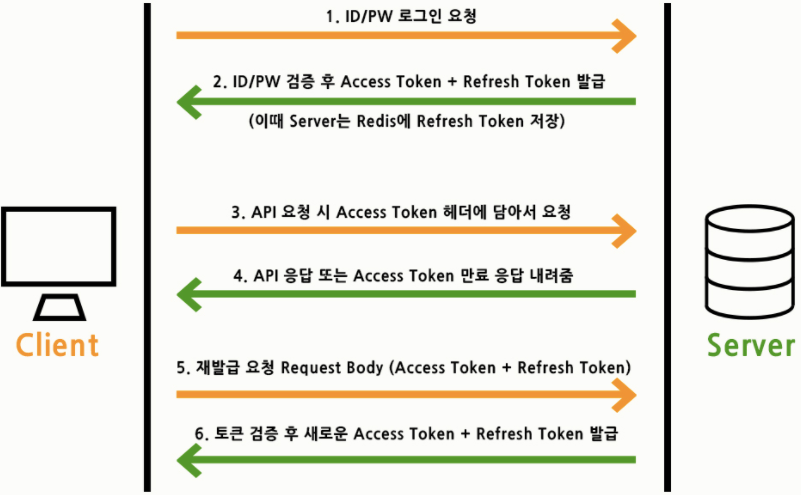
- 사용자가 로그인하면 access token, refresh token이 발급된다.
- access token은 클라이언트 측에서 들고 있기 때문에 언제든 탈취당할 위험성이 있다.
- 그래서 access token은 아주 짧은 expiration period를 가져가고
- 기간이 만료된 access token은 refreshte token을 이용해 재발급받는다.
- 보통 access token은 짧게 (10분), refresh token은 보다 길게(하루) 만료기간을 잡는다. https://blog.naver.com/PostView.naver?blogId=jinwoo6612&logNo=222462211251&parentCategoryNo=&categoryNo=32&viewDate=&isShowPopularPosts=true&from=search
Transaction
- db의 데이터를 조작하는 작업의 단위이다.
- A가 B에게 1000원 송금한다. → 하나의 트랜잭션 작업
- UPDATE 문을 사용해 사용자 A의 잔고를 변경
- UPDATE 문을 사용해 사용자 B의 잔고를 변경
- 이렇게 2개의 쿼리문 모두 성공해야지만 하나의 작업(트랜잭션)이 완료된 것이다. → Commit
- 작업 단위 중 하나의 쿼리라도 실패하면 모든 쿼리문을 취소하고 이전의 상태로 돌려놓는다. → Rollback
- 특징 : 원자성 / 일관성 / 독립성 / 지속성 (ACID)
- 한 트랜잭션이 DB를 다루는 동안 다른 트랜잭션은 DB에 관여하지 못하도록 막는 것이 Locking인데, 무조건 Locking을 통해 수많은 트랜잭션을 순서대로 처리하도록 대기시키는건 성능이 떨어진다. 그렇다고 Locking의 범위를 줄인다면 잘못된 값이 처리될 문제가 생긴다. 이를 효율적으로 관리하기 위해 격리 수준이 필요하다.
- 격리 수준 (Isolation 4 level)
- Read Uncommitted : 트랜잭션이 끝나기도 전에 트랜잭션 내부에서 쿼리가 실행되어 변경된 값을 읽어버린다.
- Read Committed : 트랜잭션이 끝나야지만 변경된 값을 읽을 수 있고 끝나기 전엔 본래 상태의 데이터를 읽는다.(실제 데이터가 아닌 undo영역에 백업된 레코드의 값) 1번 트랜잭션 기간동안 다른 2번 트랜잭션(DML)이 수행되면 2번 트랜잭션이 끝나는 시점을 기준으로 select되는 데이터가 달라질 수 있다. (= Unrepeatable Read)
- Repeatable Read : 하나의 트랜잭션에서 처음으로 select를 수행한 시점을 기록한 뒤 해당 스냅샷 기준으로 이후 모든 select를 수행한다. 반복적으로 읽어도 (Repeatable Read) 항상 같은 값을 읽어들인다.
-
Serializable : Phantom Read가 발생하지 않는다. 대신 쉽게 DeadLock에 빠질 수 있다.
(A-1) SELECT state FROM account WHERE id = 1; (B-1) SELECT state FROM account WHERE id = 1; (B-2) UPDATE account SET state = ‘rich’, money = money * 1000 WHERE id = 1; (B-3) COMMIT; (A-2) UPDATE account SET state = ‘rich’, money = money * 1000 WHERE id = 1; (A-3) COMMIT;- (A-1)번
SELECT쿼리가SELECT ... FOR SHARE로 바뀌면서 id = 1 인 row에 S Lock을 건다. - (B-1)번
SELECT쿼리 역시 id = 1인 row에 S Lock을 건다. - A와 B가 각각 (B-2), (A-2)
UPDATE쿼리를 실행하려고 하면 row에 X Lock을 시도한다. - 이미 해당 row에는 S Lock이 걸려있어
DEADLOCK상황에 빠진다. - 두 트랜잭션 모두
DEADLOCK으로 인한 Timeout으로 실패하여 데이터는 변경되지 않고 원래대로 남아있게 된다. - Phantom Read : Read Committed와 Repeatable Read는 하나의 트랜잭션에서 select → update → select를 했을 때 변경된 값을 제대로 읽지 못하고 유령의 값을 읽는 상황이 발생할 수 있다.
- (A-1)번
- https://nesoy.github.io/articles/2019-05/Database-Transaction-isolation
- https://velog.io/@lsb156/Transaction-Isolation-Level
NoSQL vs RDB
- SQL
- 데이터는 정해진 데이터 스키마에 따라 테이블에 저장된다. (데이터 무결성 보장)
- 데이터는 관계를 통해 여러 테이블에 분산된다. 이를 통해 데이터의 중복이 발생하지 않아서 다른 테이블에서 부정확한 데이터를 다룰 위험이 아예 없어진다.
- 트랜잭션, ACID 등을 관리하는 데에 들어가는 비용 때문에 이를 관리하지 않는 NoSQL에 비해 성능이 떨어진다.
- USE CASE
- 데이터 구조가 변경될 여지가 없고, 명확한 스키마가 필요한 경우
- 관계를 맺고 있는 데이터가 자주 변경될 경우
- NoSQL
- TTL → Time to Live 특정 행이 TTL시간 이후엔 자동으로 삭제되는 기능을 제공한다.
- 컬렉션엔 특정 스키마가 없다. 그래서 서로 다른 구조의 데이터들이 같은 컬렉션에 다큐먼트로 들어올 수 있다.
- 조인을 할 필요 없이 애초에 조인이 된 상태로 다큐먼트가 생성된다.
- 자주 변경되지 않는 데이터일 때 효율적이다.
- 데이터가 여러 컬렉션에 중복되어 있으면 수정할 때 모든 컬렉션에서 데이터 중복을 업데이트하는건 매우 불편
- USE CASE
- 정확한 데이터 구조를 알 수 없고, 계속 변경/확장이 되는 경우
- 읽기를 자주 하고, 데이터의 변경은 거의 없는 경우
- DB서버의 CPU 성능 등을 업그레이드 시키는게 수직적 확장
- DB서버를 추가로 많이 늘려서 데이터베이스를 분산시키는 수평적 확장, 즉 샤딩을 지원한다. (SQL에선 불가능)
- https://siyoon210.tistory.com/130
댓글남기기