
DB (1)
Index
-
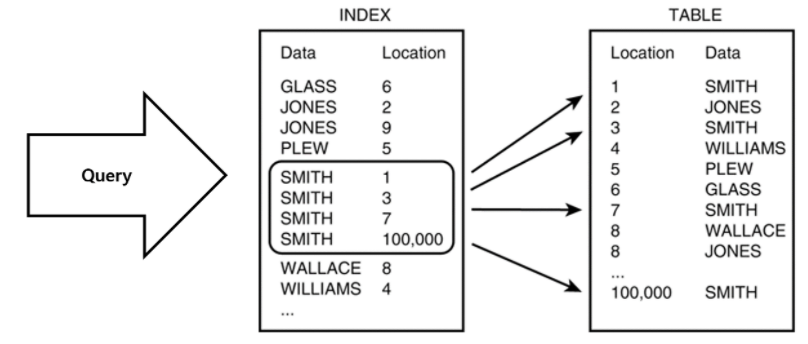
인덱스란?
- 쿼리 속도 (검색 속도)를 높이기 위한 색인 기술이다.
- 인덱스 테이블에 있는 행들은 항상 정렬되어있다.
- 인덱스 걸리면 좋은 조건의 컬럼
- 주로 where, join, order by절에 쓰이는 컬럼을 인덱스로 잡는 것이 좋다.
- 카디널리티가 높은 → 해당 컬럼에 중복되는 값이 적은 컬럼 (이름은 동명이인이 있을 수 있어 중복 가능이지만, 사번(gm2202988)은 무조건 다르게 생성되므로 중복도가 낮고 카디널리티가 높다.)
- DML 등의 작업으로 인한 컬럼의 수정 빈도가 낮을 수록 좋다.
- boolean 컬럼에 인덱스를 건다면?
- boolean 컬럼은 모든 로우에 대하여 true or false이므로 카디널리티가 매우 낮다. (중복도가 매우 높다.)
- true or false로 그룹지어진 그룹들엔 그룹에 편성되는 데이터의 수가 결국 전체 데이터를 2개의 분류로 나눈 꼴이라 인덱스의 효율이 없다시피 하다.
- 모든 컬럼에 인덱스를 걸면 안되는 이유
- 인덱스도 하나의 자료구조(B-TREE)로 디스크에 저장되어 사용된다. (인덱스 테이블로)
- 쿼리가 들어오면 디스크에서 인덱스 테이블을 읽는 작업이 필수이다. 인덱스가 과하게 많으면 디스크I/O 연산이 많아진다.
- 인덱스는 항상 정렬된 상태를 유지해야 한다.
- 행이 삽입, 수정, 삭제될 때(DML)마다 똑같이 인덱스 테이블에서도 키의 추가, 삭제가 이루어진다. 따라서 작업의 오버헤드가 증가한다.
-
인덱스를 타지 않는 쿼리
- 인덱스 컬럼이 변형되어서 검색이 들어가는 경우
select * from where to_char(indexed_colunm, 'YYYYMMDD') = '20211215'; - 내부적으로 데이터 형 변환이 이루어진 경우
# indexed_colunm은 int형 select * from where indexed_colunm = '20211215'; - 부정 연산자(!=,<>,NOT IN, NOT EXISTS)를 사용
select * from where indexed_colunm != 20211215; - OR 구문을 사용
# 복합 인덱스(indexed_colunm, name)이 걸려있어도 이 인덱스를 안 탄다. select * from where indexed_colunm = 20211215 or name = 'kmk'; - LIKE을 사용하는데 문자열 맨 앞에 %를 사용하는 경우
select * from where name like '%kmk%'; -
결합 인덱스에서 순서상 뒤에 있는 컬럼이 조건으로 들어갈 때
# 결합 인덱스 생성 create index emp_pay_idx on emp_pay(급여년월, 급여코드, 사원번호); # 인덱스를 타는 경우 select * from emp_pay where 급여년월 = '202107'; select * from emp_pay where 급여년월 = '202107' and 급여코드 ='정기급여'; select * from emp_pay where 급여년월 = '202107' and 급여코드 = '정기급여' and 사원번호 = '20210401'; # 인덱스가 타지 않는 경우 select * from emp_pay where 급여코드 = '정기급여'; select * from emp_pay where 사원번호 = '20210401'; select * from emp_pay where 사원번호 = '20210401' and 급여코드 = '정기급여';
- 인덱스 컬럼이 변형되어서 검색이 들어가는 경우
- 인덱스 자료구조
- hash table
- key-value형태이다. key는 데이터(컬럼의 값)이고 value는 데이터의 위치이다.
- 시간 복잡도가 O(1)이다. 검색이 매우 빠르다.
=조건에서만 쓸 수 있다.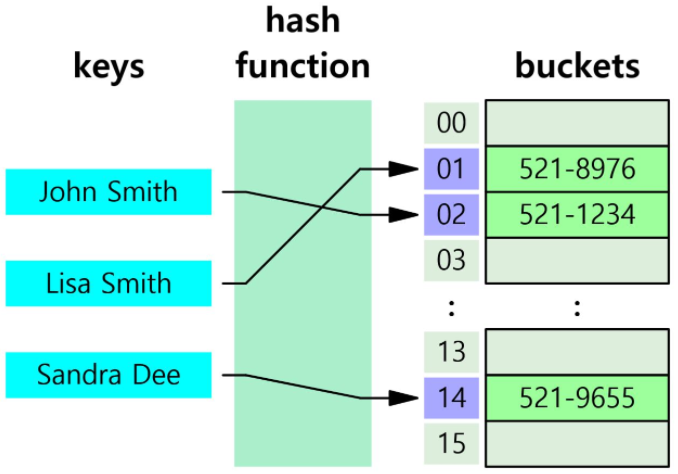
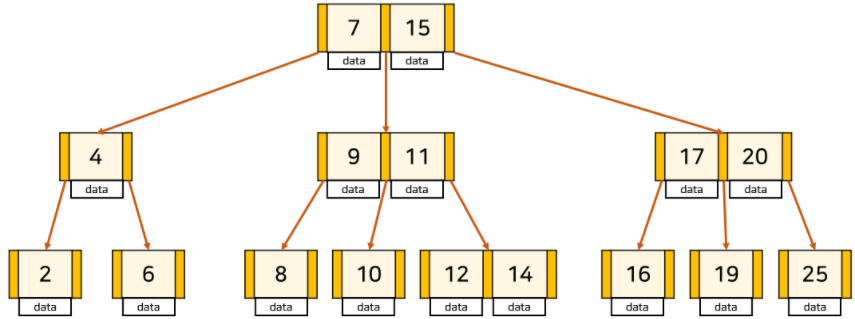
- B-Tree
- 자식 노드가 2개 이상인 트리
- 하나의 노드에 여러 데이터가 포함될 수 있으며 각 노드에서의 데이터들은 항상 정렬된 상태이다.
- 시간복잡도는 조회, 삭제, 삽입, 수정 모두 O(logN)
- 균형트리로 루트노드로부터 리프노드까지의 거리가 모두 일정한데
- 데이터의 삭제, 삽입, 수정이 일어나면 트리의 균형을 유지해줘야 하므로(정렬된 상태 유지) 트리의 변형이 발생할 수 있다. (효율이 좋지않다.)
- 또한 full scan을 할 때 모든 노드를 순회해야한다는 단점이 있다.
- 이를 해결하고자 나온 것이 B+Tree이다.
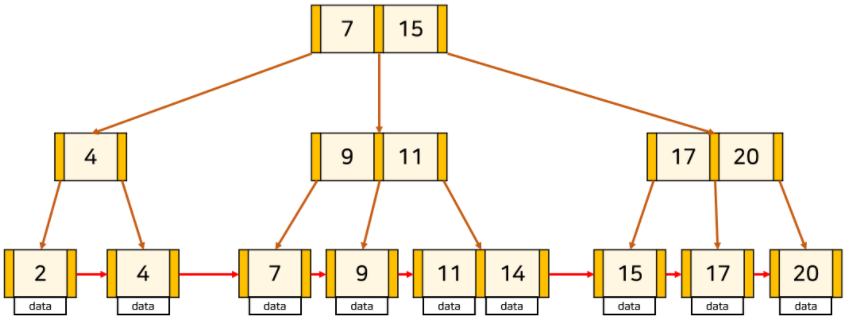
- B+Tree
- 리프노드에만 데이터가 들어있고 나머지 노드엔 자식 포인터만 존재한다.
- 그래서 B-Tree에 비해 차지하는 메모리가 작다.
- 리프노드까지 무조건 깊이 들어가야한다는 단점이 있다. (B-Tree에선 리프보다 루트노드에 가까운 브랜치노드에서 찾으면 더 깊이 안들어가도 됨)
- 리프노드들끼리 Linked List 자료구조로 연결되어 있어서 순회한다.
- 리프노드에만 데이터가 있기 때문에 리프노드와 나머지 노드에서 키가 중복될 수 있다.
- 리프노드를 제외한 나머지 노드에서 더 많은 포인터를 저장할 수 있어서 트리의 높이는 낮아지고 그로 인해 검색 속도는 더 빨라진다.
- full scan을 할 때 데이터가 존재하는 리프노드에선 전부 linked list로 연결되어 있기 때문에 선형시간이 걸리지만 B-Tree에선 모든 노드를 순회해야 한다.
- 왜 배열은 안될까?
- 정렬되어있는 배열에서 값을 찾는 방식은 사실 최고다.
- 하지만 정렬되어있는 배열에서 값을 삽입, 수정, 삭제하는 건 굉장히 효율이 안나온다. 삽입을 예시로 특정 값이 들어갈 위치를 찾고(1), 위치에 값을 넣은 후에 나머지 값의 인덱스들을 하나씩 밀어내(2)야 하기 때문이다. O(N)
- https://helloinyong.tistory.com/296
- https://junhyunny.github.io/information/data-structure/db-index-data-structure/
- hash table
댓글남기기